


Recogni разворачивается в сторону чипов вывода искусственного интеллекта для дата-центров
САН-ХОСЕ, Калифорния. – Recogni, стартап по разработке чипов периферийного ИИ, ранее разрабатывавший ускорители для автомобильного сегмента, развернулся в сторону вывода генеративного ИИ в дата-центрах и собирается разрабатывать второе поколение своих чипов именно для этого рынка.
Компания рассчитывает применить свой опыт работы с логарифмической системой счисления (LNS) для вывода ИИ и масштабирования, рассказал соучредитель и директор по продукции (CPO) компании Recogni Р.К. Ананд.
«Математика предоставит нам явные преимущества и позволит хорошо позиционировать себя на рынке вывода GenAI», — сказал он. «Основные затраты — это обучение моделей, а основная прибыль — это вывод ИИ, и пока вы не зарабатываете на выводе, доступного ИИ не будет. Наша работа заключается в предоставлении технологий и систем, которые делают вывод рентабельным и, следовательно, широко применимым».
Логарифмизация системы счисления
Сама по себе LNS не нова. Операции сложения всегда реализовалась относительно легко «на кремнии», однако умножение требовало большей площади кристалла. Преобразование чисел в логарифмический домен позволяет заменить умножение менее накладным сложением, делая операцию сложения, наоборот, более непростой. Сложение в LNS обычно выполняется с помощью очень неэффективных таблиц поиска. Если рабочие нагрузки содержат больше умножений, чем сложений (как это часто бывает в работе цифровых сигнальных процессоров (DSP)), подобный компромисс может быть оправдан. Проблема в том, что вывод ИИ является «тяжёлым» с точки зрения алгоритма умножения матриц, то есть имеет примерно равное количество умножений и сложений.
Чтобы LNS заработала для вывода ИИ, нужно найти более эффективный способ обработки сложений, поскольку тысячи необходимых таблиц поиска потребуют непомерного объема памяти, особенно для высокой (например, 16-битной) точности, объясняет соучредитель и вице-президент Recogni по ИИ Жиль Бэкхус.
Вместо таблиц поиска можно было бы использовать процессор для расчёта ряда Тейлора, добавляет Бэкхус, но это также вычислительно затратно и относительно медленно. Вместо этого Recogni аппроксимирует умножения сложениями, основываясь на хорошо известном приближении:
log 2 (1+x) = x для 0<x<1
Подобная аппроксимация использовалась в первом поколении чипа от Recogni, но для хороших результатов требовался метод «обучение с учетом квантования» (QAT). Первый чип от Recogni разрабатывался для сетей с задачами, требующими менее 100 миллионов параметров на приложение, где QAT не было особенно важным. Но сегодня большие языковые модели (LLM) могут быть на много порядков сложнее. QAT требует также полного доступа к набору данных для обучения, что сегодня не всегда возможно, сказал Бэкхус.
«С точки зрения программного обеспечения, QAT будет ужасным испытанием для нашего дата-центра, поскольку нам придётся вступить в область обучающего ПО», — говорит он. «Клиент не захочет этого делать. Мы хотим сохранить программную сторону исключительно ясной и простой. К тому же это одна из главных причин, по которой сторонние чипы не могут быть использованы клиентами».
Без QAT замена умножения сложением была непростой задачей. Средняя ошибка при аппроксимации положительна, что сильно влияет на обобщённую ошибку, особенно с учётом большого количества операций. Поэтому аппроксимация нуждалась в «доводке». Подобные доводки являются большой частью решения от Recogni.
«Разумно было что-то добавить к аппроксимации, оставаясь недорогим решением в мире битовых сдвигов, каскадных подключений, усечений и округлений, и при этом снизить среднюю ошибку примерно до одной сотой [по сравнению с исходным приближением]», — рассказывает Бэкхус. «И сразу появляется свободный от таблиц поиска, свободный от рядов Тейлора, но все еще чрезвычайно дешевый способ конвертировать логарифмические числа в линейные. Это наш секретный ингредиент».
При тестировании доводок основная часть работы приходится на проверку того, как всё будет функционировать более чем на одном слое или одной матрице при операциях умножения, поскольку ошибки нелинейно накапливаются при каждой операции, и получаемая измененная аппроксимация является сложным балансом между точностью и эффективностью вычислений. Бэкхус говорит, что было рассмотрено около восьми различных вариантов аппаратной реализации.
Математика от Recogni совершенно удалила QAT из процесса. Результатом стала новая числовая система по «принципу Парето». Переключение на Парето с помощью квантизатора от Recogni обеспечивает точность на уровне 99,97% от оригинала для Llama2-70B и 99,91% для Llama3.1-405B. (Со схожими результатами Recogni также преобразовала модели наподобие Falcon, Mixtral и StableDiffusion).
Также компания много поработала над своей математикой, чтобы гарантировать, что эффект малых чисел не потерян при округлении (и всё еще влияет на результат), и что динамический диапазон достаточен для покрытия отклонений в данных. Парето предлагает различную степень точности (до 16 бит), а оборудование поддерживает смешанную точность на высоком уровне детализации (вплоть до одного ряда матрицы). Команда Recogni по квантованию разрабатывает методы автоматизации смешанной точности.

Система чисел Парето компании Recogni обеспечивает лучший охват чисел, стремящихся к нулю, чем целочисленные форматы с аналогичным динамическим диапазоном, но требует при этом меньшей площади кристалла. (Источник: Recogni)
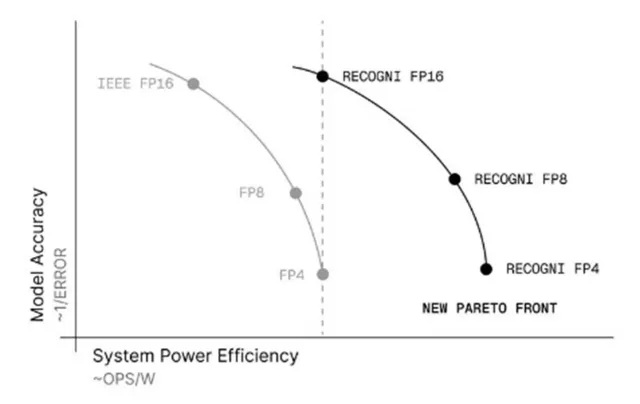
Recogni утверждает, что 16-битный формат Парето на их собственном оборудовании обеспечит энергоэффективность, сопоставимую с реализациями FP4 на другом оборудовании, обеспечивая при этом и повышение точности. (Источник: Recogni)
В первом поколении технологий Recogni ключевой была концепция «кластеризации» или «бакетирования» (хэш-кластеризации) нагрузок для уменьшения сетей. По утверждению Бэкхуса, теперь эта техника неактуальна.
«Можно применить эту технику и к трансформерам, но в этом нет необходимости», — сказал он. «На нашем первом чипе была только память самого чипа, поэтому нам приходилось быть крайне осторожными в её использовании. Подход с компрессией кластера был очень успешным, так как позволил нам серьёзно сократить нагрузки без существенной потери точности. Но сегодня, поскольку мы будем использовать память с высокой пропускной способностью, проблема ёмкости памяти не стоит».
Уменьшение некоторых нагрузок до 8 или 4 бит также может помочь в случае, если пропускная способность памяти останется узким местом, добавил Бэкхус.
Recogni владеет патентом на внедрение логарифмических систем счисления (LNS) для вывода ИИ.
Системная инженерия
Реализация преимуществ системы чисел Парето от Recogni требует специализированного оборудования, над которым работает компания. Так как вывод ИИ является масштабируемой задачей, где общая производительность зависит от проблем системного уровня (таких как сетевое взаимодействие), это потребует превращения в системную компанию, сказал Ананд. Цель заключается в разработке чипа вывода ИИ для дата-центров, который в конечном итоге будет продаваться как часть стоечных систем, разработанных компанией, хотя это всё ещё продукт из разряда «более чем через год», утверждает Ананд.
Recogni проводит испытания на собственной одностоечной системе, обеспечивающей производительность 320 000 токенов/с для Llama3.1-405B (2304 одновременных пользователей), сокращая «время до первого токена» (TTFT) в 3 раза, а «время на вывод токена» (TPOT) в 6,4 раза по сравнению с системой эквивалентного масштаба на базе Nvidia H200.
В то же время, комплект средств разработки ПО, который будет выпущен в ближайшее время, позволит разработчикам преобразовывать свои модели в модели Парето и измерять точность, чтобы «удостовериться в наших математических расчетах», сказал Ананд.




